1. HASHING
Hashing adalah sebuah data struktur dengan fungsi bernama "Hash Function" yang dapat mempersingkat proses untuk mengakses suatu element di dalam list.
Hash table adalah table yang berfungsi untuk menampung value dan index dari sebuah key. value berisi string dan index berisi hashed key dari string tersebut.
Cara mendapatkan hashed key dari sebuah string adalah dengan menggunakan sebuah formula/metode yang mempersingkat string tersebut.
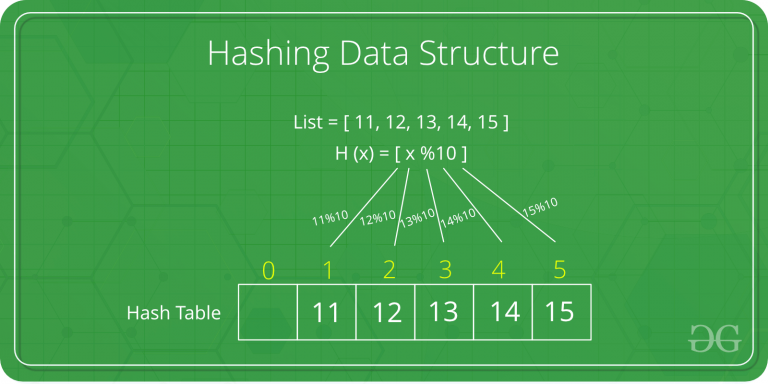
Sebagai contoh, terdapat sebuah list yang berisi 11, 12, 13, 14, 15. salah satu cara untuk mendapatkan Hashed Key dari masing masing data adalah dengan metode "Division", yaitu dengan fungsi
H(x) = [x % M),
x = key
M = value yang digunakan untuk membagi key, biasa berupa angka prima, size dari hash table, atau size dari memory yang digunakan.
*Metode Division adalah Metode yang paling sering digunakan umumnya.
Berikut adalah metode yang dapat digunakan sebagai Hash Function:
1. Mid-square
Men-kuadratkan value dari key, lalu mengambil nilai pada digit tengah sebagai hashed key.
contoh : key = 3121
squared value = 9740641
hashed key = 406
2. Division
3. Folding
Membagi key menjadi beberapa part, setiap part berisi paling banyak 2 digit, kemudian menjumlahkan setiap partnya.
4. Digit extraction
Menentukan digit berapa saja yang akan digunakan untuk mengambil nilai sebagai Hashed key.
contoh: digit 1, 3, 5. key = 123456. hashed key = 135.
5. Rotating Hash
Dimulai dengan menggunakan metode 1,2,3,4, dan merotate hashed key.
contoh: hashed key = 40989. rotate menjadi 98904.
Collision
yaitu sebutan apabila ada 2 key yang memiliki hashed key yang sama, istilahnya bertabrakan.
contoh:
jika ada hash function yang mengambil char paling pertama, maka string Andi dan Anton akan memiliki hashed key yang sama yaitu 0. (karena A=0, B=1, C=2, dst).
Untuk mengatasi collision, digunakan 2 cara, yaitu:
1. Linear Probing
Dengan mencari tempat yang kosong selanjutnya pada table.
Misal jika tadi Andi ditempatkan pada 0, maka Anton ditempatkan pada 1.
Namun linear probing sedikit tidak efektif karena dapat melakukan banyak perulangan untuk mencari value yang memiliki hashed key yang sama.
Misal jika urutan stringnya adalah Andi, Budi, lalu Anton, maka Andi=0, Budi=1, Anton=2.
sedangkan Anton seharusnya 0, maka akan dicari index 0 dan jika bukan anton, akan melakukan iterasi hingga menemukan value Anton.
2. Chaining
Metode ini menggunakan Linked List, jadi jika ada string Andi, Budi Anton
Andi=0, Budi = 1, Anton = 0 -> next.
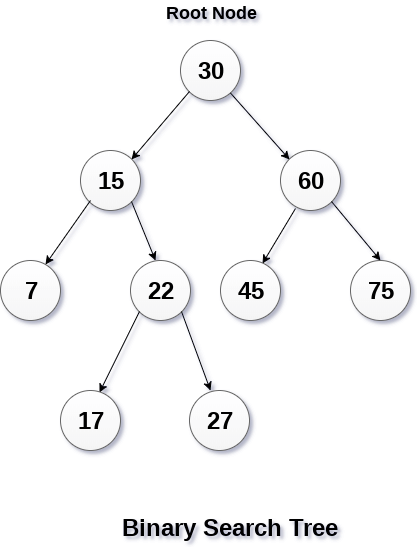
2. BINARY TREE
Binary Tree adalah bentuk dari tree dimana tiap node hanya dapat memiliki cabang maksimum 2 (left and right).
 |
| Contoh BINARY TREE |
*Node paling atas disebut root.
jadi root pada gambar : 8
*Node yang tidak memiliki child disebut leaf.
jadi leaf pada gambar : 1,4,7,13
Binary Tree dibagi lagi menjadi 4 type :
1. Perfect Binary Tree (termasuk complete binary tree, setiap level memiliki depth yang sama)
2. Complete Binary Tree (setiap level, kecuali terakhir, memiliki depth yang sama)
3. Skewed Binary Tree ( setiap node hanya memiliki 1 child)
4. Balanced Binary Tree (suatu leaf tidak melebihi leaf lainnya sebanyak 1)
Binary Tree dapat direpesentasikan dengan menggunakan Array dan Linked List
*Array
*Linked List