LINKED LIST
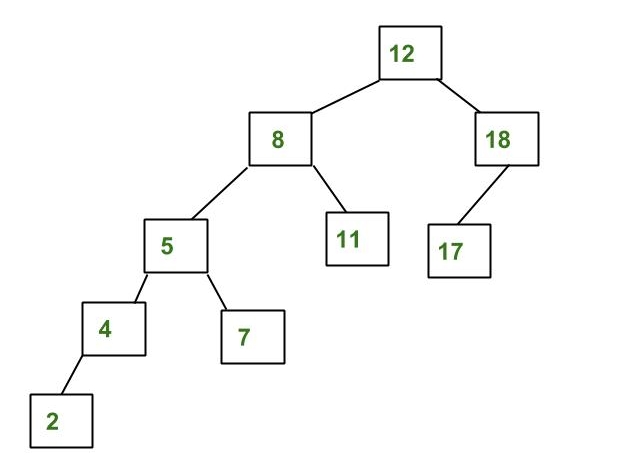
linked list adalah sebuah kumpulan data yang dapat berupa string, characters, numbers, etc.
linked list sendiri dalam pemrograman dapat dibandingkan dengan array, karena keduanya memiliki persamaan yaitu merupakan kumpulan dari data.
yang membedakan adalah linked list dibuat dalam sequence, yaitu misalnya data 1 berhubungan dengan data 2, data 2 berhubungan dengan data 3, dst.
STACK
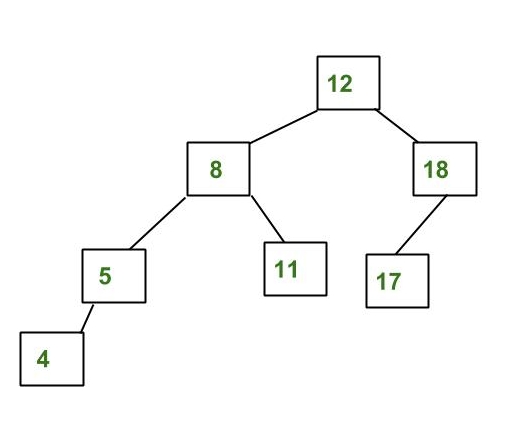
stack adalah data structure yang menyimpan kumpulan element, mirip seperti array dan linked list.
namun, operasi pada stack yaitu insert dan deletion hanya dapat dilakukan pada 1 sisi, yang umumnya disebut "TOP".
prinsip stack yaitu last-in first-out (LIFO)
operation pada stack:
1. push() : yaitu untuk menambahkan suatu element / item paling atas
2. pop() : untuk memindahkan / remove suatu element yang paling atas
3. top() : untuk mengembalikan nilai dari element yang paling atas
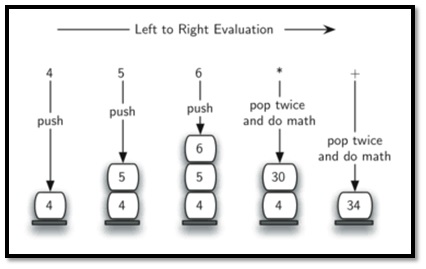 |
| 4 + 5 * 6 pada POSTFIX |
1. push(4)
2. push(5)
3. push(6)
4. pop(5), pop(6), push(5*6)
5. pop(30), pop(4), push(30+4)
result = 34
QUEUE
apabila prinsip stack adalah last-in first-out (LIFO), pada queue prinsipnya adalah first-in first-out (FIFO). inilah yang membedakan stack dengan queue.
operation dalam queue:
1. push() : yaitu untuk menambahkan suatu element / item ke antrian / queue paling belakang (rear)
2. pop() : untuk memindahkan / remove suatu element pada antrian paling depan (front)
3. front() : untuk mengembalikan nilai dari item yang berada paling depan (front) dari antrian
QUEUE PRIORITY
HASHING
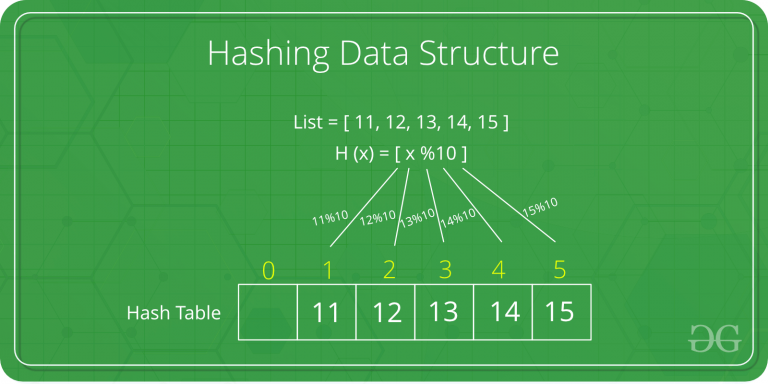
Hashing adalah sebuah data struktur dengan fungsi bernama "Hash Function" yang dapat mempersingkat proses untuk mengakses suatu element di dalam list.
Hash table adalah table yang berfungsi untuk menampung value dan index dari sebuah key. value berisi string dan index berisi hashed key dari string tersebut.
Cara mendapatkan hashed key dari sebuah string adalah dengan menggunakan sebuah formula/metode yang mempersingkat string tersebut.
Sebagai contoh, terdapat sebuah list yang berisi 11, 12, 13, 14, 15. salah satu cara untuk mendapatkan Hashed Key dari masing masing data adalah dengan metode "Division", yaitu dengan fungsi
H(x) = [x % M),
x = key
M = value yang digunakan untuk membagi key, biasa berupa angka prima, size dari hash table, atau size dari memory yang digunakan.
Berikut adalah metode yang dapat digunakan sebagai Hash Function:
1. Mid-square
Men-kuadratkan value dari key, lalu mengambil nilai pada digit tengah sebagai hashed key.
contoh : key = 3121
squared value = 9740641
hashed key = 406
2. Division
3. Folding
Membagi key menjadi beberapa part, setiap part berisi paling banyak 2 digit, kemudian menjumlahkan setiap partnya.
4. Digit extraction
Menentukan digit berapa saja yang akan digunakan untuk mengambil nilai sebagai Hashed key.
contoh: digit 1, 3, 5. key = 123456. hashed key = 135.
5. Rotating Hash
Dimulai dengan menggunakan metode 1,2,3,4, dan merotate hashed key.
contoh: hashed key = 40989. rotate menjadi 98904.
Collision
yaitu sebutan apabila ada 2 key yang memiliki hashed key yang sama, istilahnya bertabrakan.
contoh:
jika ada hash function yang mengambil char paling pertama, maka string Andi dan Anton akan memiliki hashed key yang sama yaitu 0. (karena A=0, B=1, C=2, dst).
Untuk mengatasi collision, digunakan 2 cara, yaitu:
1. Linear Probing
Dengan mencari tempat yang kosong selanjutnya pada table.
Misal jika tadi Andi ditempatkan pada 0, maka Anton ditempatkan pada 1.
Namun linear probing sedikit tidak efektif karena dapat melakukan banyak perulangan untuk mencari value yang memiliki hashed key yang sama.
Misal jika urutan stringnya adalah Andi, Budi, lalu Anton, maka Andi=0, Budi=1, Anton=2.
sedangkan Anton seharusnya 0, maka akan dicari index 0 dan jika bukan anton, akan melakukan iterasi hingga menemukan value Anton.
2. Chaining
Metode ini menggunakan Linked List, jadi jika ada string Andi, Budi Anton
Andi=0, Budi = 1, Anton = 0 -> next.

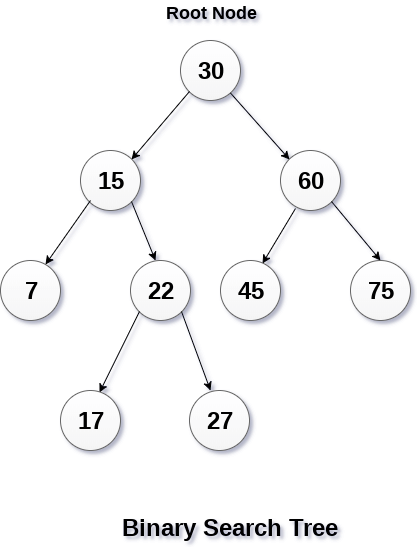
BINARY SEARCH TREE
Binary search tree(BST) adalah bentuk turunan dari binary tree. binary tree adalah tree yang hanya memiliki 2 node. pada BST, node kiri selalu bernilai lebih rendah dan node kanan selalu bernilai lebih besar.
*Dengan BST, segala insertion, deletion, dan search dapat dilakukan dalam Olog(N) (N=jumlah node pada tree). Akan berguna dalam kasus N nya berjumlah banyak.
*Karena semua tersusun dengan rapi, maka pencarian dapat dilakukan dengan mudah.
3 Operation utama dalam BST:
1. find()
2. insert()
3. remove()
INSERT()
insert(x,root)// node dimulai dari root karena root merupakan level paling dasar pada tree.
(t == null) // artinya node tersebut belum terpakai dan node baru akan disimpan di tempat itu sebagai leaf (left dan right = NULL)
//bila x lebih kecil dari node, maka lakukan insert dengan node->left sebagai node currentnya. begitu juga bila x lebih besar, maka node->right sebagai node current.
REMOVE()
untuk remove(), perlu diperhatikan apabila node yang dihapus bukan leaf (node memiliki 2 sub tree), maka node itu perlu di replace dengan kanan paling kecil atau kiri paling besar
//findMin(t->right) : untuk mencari node terkecil pada right sub tree
//node yang akan di remove di replace dengan temp
//kemudian lakukan remove pada node original yang digunakan pada temp
//deletion bisa juga menggunakan findMax(t->left) ,dengan kiri paling besar
//bila node yang ingin dihapus hanya memiliki 1 child, maka hubungkan parent dari node dengan child dari node
FIND()
//jika key lebih besar daripada current node, maka node yang dicari pasti berada di kanan current node
jika lebih kecil, maka di kiri.
DREAM MARKET ANSWER:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include <time.h>
struct tnode{
char name[26];
int qty;
int price;
struct tnode *next;
struct tnode *prev;
};
struct tnode *head = NULL;
struct tnode *tail = NULL;
int generatePrice(){
srand(time(0));
return (rand()%200+1) * 100;
}
struct tnode *createNode(char *name, int qty){
struct tnode *node = (struct tnode*)malloc(sizeof(struct tnode));
strcpy(node->name,name);
node->qty = qty;
node->price = generatePrice();
node->next = NULL;
node->prev = NULL;
return node;
}
void push(char *name, int qty){
struct tnode *node = createNode(name, qty);
if(head==NULL && tail==NULL){
head = node;
tail = node;
return;
}
struct tnode *temp;
temp = head;
int x=0;
while(temp->name[x]<=name[x]){
if(strcmp(temp->name, name)==0){
printf("Product has been listed already\n");
return;
}
while(temp->name[x]==name[x]){
x++;
if(temp->name[x]>name[x]){
if(temp == head){
node->next = head;
node->prev = NULL;
head->prev = node;
head = node;
return;
}
temp = temp->prev;
node->next = temp->next;
node->prev = temp;
temp->next->prev = node;
temp->next = node;
return;
}
}
if(temp->next==NULL){
node->prev = tail;
node->next = NULL;
tail->next = node;
tail = node;
return;
}
temp = temp->next;
x=0;
}
if(temp == head){
node->next = head;
node->prev = NULL;
head->prev = node;
head = node;
return;
}
node->next = temp;
node->prev = temp->prev;
temp->prev->next = node;
temp->prev = node;
}
void addItem(){
char name[25];
int qty;
do{
printf("Product's Name [max 25 char] : ");
getchar(); scanf("%[^\n]",&name);
} while(strlen(name)>25);
if(name[0]>='a'&&name[0]<='z'){
name[0] = name[0]-32;
}
do{
printf("Products Quantity [max 999] : ");
scanf("%d",&qty);
} while(qty>999);
push(name, qty);
printf("Press Enter to Continue . . .\n");
getchar();getchar();
}
void edit(){
struct tnode *temp;
char name[25];
int flag = 0;
int qty;
do{
temp = head;
printf("Product's Name [0 to cancel] : ");
getchar(); scanf("%[^\n]",&name);
if(name[0]>='a'&&name[0]<='z'){
name[0] = name[0]-32;
}
if(strcmp(name,"0")==0){
return;
} else {
while(temp!=NULL){
if(strcmp(name, temp->name)==0){
do{
printf("Products Quantity [max 999] : ");
scanf("%d",&qty);
} while(qty>999);
temp->qty = qty;
printf("Product has been updated\n");
printf("Press Enter to Continue . . .\n");
getchar();getchar();
return;
}
temp = temp->next;
}
}
printf("Product not found\n");
} while(true);
}
void remove(){
struct tnode *temp;
char name[25];
int qty;
do{
temp = head;
printf("Product's Name to be deleted [0 to cancel] : ");
getchar(); scanf("%[^\n]",&name);
if(name[0]>='a'&&name[0]<='z'){
name[0] = name[0]-32;
}
if(strcmp(name,"0")==0){
return;
} else {
while(temp!=NULL){
if(strcmp(name, temp->name)==0){
if(temp == head && temp == tail){
head = NULL;
tail = NULL;
free(temp);
} else if(temp == head){
head = head->next;
head->prev = NULL;
free(temp);
} else if(temp == tail){
tail = tail->prev;
tail->next = NULL;
free(temp);
} else{
temp->next->prev = temp->prev;
temp->prev->next = temp->next;
free(temp);
}
printf("Product has been deleted\n");
printf("Press Enter to Continue . . .\n");
getchar();getchar();
return;
}
temp = temp->next;
}
}
printf("Product not found\n");
} while(true);
}
void checkout(){
struct tnode *temp = head;
int totalPrice = 0;
int i=0;
printf("===================================\n");
printf("| BILL |\n");
printf("===================================\n");
while(temp!=NULL){
printf("| %-31s |\n",temp->name);
printf("| %3d x %-6d : %-15d |\n",temp->qty,temp->price, temp->price*temp->qty);
printf("| |\n");
totalPrice += temp->price*temp->qty;
temp = temp->next;
i++;
}
printf("| Total : Rp.%-10d |\n",totalPrice);
printf("===================================\n");
printf("| ~Kindness Is Free~ |\n");
printf("===================================\n");
}
void printMenu(){
struct tnode *temp = head;
printf("==================================================\n");
printf("| WELCOME TO THE MINIMARKET |\n");
printf("==================================================\n");
int i = 0;
while(temp!=NULL){
printf("| %3d. | %-25s | %-3d | %-5d |\n",i+1, temp->name, temp->qty, temp->price);
temp = temp->next;
i++;
}
printf("==================================================\n");
printf("1. Add Item\n");
printf("2. Edit Item\n");
printf("3. Delete Item\n");
printf("4. Checkout\n");
printf(">> ");
}
int main(){
int choose;
do{
printMenu();
scanf("%d",&choose);
switch (choose){
case 1:
addItem(); break;
case 2:
edit(); break;
case 3:
remove(); break;
case 4:
checkout(); break;
}
} while(choose!=4);
return 0;
}
 Hasil Visualisasi dan Penjelasan
Hasil Visualisasi dan Penjelasan